March 10, 2025
The Helper Bees has built a digital data acquisition platform that provides long-term care insurance partners with transformative digital invoicing solutions for home and facility-based care. Here we demonstrate the true capabilities of an all-digital data acquisition method with dashboard-style data summaries of individual claimants, empowering carriers to extrapolate trends in health and care, detect possible fraud, and review policy usage and changes in care. Additionally, The Helper Bees has built systems that report directly on aspects of the overall care block, such as cost savings, possible fraud, inactivity, and underutilization of care. These systems enable our partners to generate real-time reports to provide data-driven, personalized care. Most recently, carriers have used the systems to visualize and adapt to the evolving impact of COVID-19 on home care claims.
Our proprietary model can reliably predict 97% of our claimants’ needs regarding the degree of services rendered by our caregivers through both the matching and electronic visit verification products, something we have termed the “intensity of utilization.” This model has a high degree of correlation between our assessments of claimants’ needs and their utilization (r2 = 0.98). We can now anticipate an 8.9% increase in our services rendered scores for every 10% increase in our scores assessing our claimants’ needs. Not only did the subset analysis show a similar linear regression, but more importantly, it showed a similar frequency and distribution of outliers. It is important to note, the sample data sets were chosen before and after our claimant volume soared 9-fold in response to the COVID-19 pandemic. Therefore, these data sets validate our model’s performance independent of time and seasonal variables. Most importantly, it demonstrates that our model can scale and still perform with fantastic precision.
This exclusive model predicts the needs of claimants based on their caregiver’s assessments. When claimants are underutilizing services based on this model, we can intervene with targeted reassessment and interventions since these claimants are at the highest risk for institutionalizations, injuries, emergency services, etc. This model also reliably identifies the 2–3% of claimants that warrant reviews, assessments, and interventions. When claimants overutilize services based on our model, we can reevaluate their assessments and assist our partners with investigations into fraudulent activity. This data-driven approach maximizes claimant satisfaction and retention while minimizing expenses for our partners.
The Helper Bees was founded in 2015 to modernize and disrupt the long-term care industry. The current model is outdated and expects to take people out of their own homes’ comforts and plug them into legacy systems like nursing homes, assisted living centers, subacute nursing facilities, and even hospitals. Our mission at The Helper Bees has always been to build a system around our individual claimants. We believe it is not only ignorant to ignore the individual needs and desires of people, but also dangerous and costly, with increased rates of deleterious outcomes.
We understand and prioritize people’s desires to age in place. We are building a people-centric system around our claimants. This includes, but is not limited to, individualized match-making services for the perfect in-person caregivers, a Concierge Care Team, and Virtual Benefit Assessments.
The Helper Bees built a platform that connects digital invoicing and claims management tools with dashboard-style data summaries of individual claimants, allowing large insurance carriers to extrapolate trends in health and care and detect possible fraud, review policy usage, and examine changes in care. Additionally, The Helper Bees built the systems that directly report aspects of the overall claims block, such as cost savings, possible fraud, inactivity, and underutilization of care. These systems enable our partners to generate real-time reports on the fly, realize continuous ROI in a challenging and dynamic industry, and provide data-driven, personalized care.
What further distinguishes us from our competitors is our dedication to data gathering and analysis. Data analytics is the cornerstone of our success and makes the systems mentioned possible. Machine learning algorithms match claimants to their ideal caregivers, maximizing claimant satisfaction. Superior matching, in turn, translates to increased revenues for insurance partners by increasing enrollment through referrals and increasing policy retention rates. We also successfully utilized machine learning algorithms to streamline our virtual benefits assessments, which dramatically improves efficiency, giving us the bandwidth to handle a 9-fold surge in volume and demand secondary to the COVID-19 pandemic. Finally, in addition to allowing for maximized efficiency, our model successfully predicts and anticipates claimants’ needs. For claimants whose needs fall outside of our model, we focus on early interventions, detailed assessments, and reviews to minimize the incidence of institutionalization, injuries, and deaths, priorities for both our claimants and our long term care insurance partners.
This white paper will focus on how we validated our model for predicting the needs of our claimants. Based on this model, we will also launch a series of case reports investigating the circumstances surrounding claimants that fall out of our model, termed the “outliers.” We also have preliminary data, to be featured in an upcoming white paper, validating our model independent of the caregiver. Finally, we also plan to publish white papers demonstrating how The Helper Bees model can maximize the efficacy of fraud investigations and early interventions intended to minimize institutionalization rates by focusing on a specific subset of these outliers.
Since the inception of The Helper Bees, we have collected various data points on each of our claimants. These data are standardized and categorized into several databases that include invoices, timesheets, assessments, and insurance claims. Using these databases, we have built a model that predicts our customers’ needs within a high degree of certainty.
First, we designed a simple, reproducible scoring system with high inter-rater reliability to quantify both the assessment of our claimants’ needs and the degree of services provided by our caregivers (intensity of utilization). To learn more, read the published Medium article “Industry First Activity of Daily Living Scoring Uncovers Results in Level of Care Needed.” (Hu, 2020). This proprietary scoring system is the crux of our model; therefore, high inter-rater reliability is imperative. Our caregivers assess the needs of claimants in person. They quantify claimants’ needs in an assessment containing a series of categories with a score of 0 or 1. This binary or yes/no assessment helps eliminate subjectivity and maximize inter-rater reliability. The sum of these individual scores represents the overall assessment of our claimants’ needs.
Previously in this white paper, we alluded to the fact that we have preliminary data on claimants who have switched caregivers. This data shows high kappa scores between caregivers’ assessments of claimants, which translates to high inter-rater reliability. However, the data set for this analysis is limited. The fact that there is little data from claimants who have switched caregivers is a testament to our machine algorithms’ success, which successfully match claimants to caregivers they use consistently over long periods of time. But as this data set grows, we look forward to publishing the data that shows how our simple scoring system is both effective and has high inter-rater reliability.
Our scoring system that quantifies the degree of the services provided by our caregivers to our claimants is termed the “intensity of utilization.” Similar to the assessment of our claimants’ needs, the intensity of utilization is also assessed by our caregivers. However, these assessments are based on metrics provided on timesheets used to file claims with insurance companies. These timesheets have to be reviewed and signed off by both caregivers and claimants. This agreement between caregivers and care recipients provides the validation of the metrics used to build our quantitative assessment of the intensity of utilization. So again, our assessment of our claimant’s needs are validated based on high inter-rater reliability scores, and our assessment of the intensity of utilization is validated by agreement between the caregiver and the care recipient (our claimants).
Our system for quantifying the caregivers’ services is based on a scoring system of 1 to 3 for each service provided. If a certain service was not provided, then it is given a score of 0. The sum total of these scores is used to represent the intensity of utilization of our claimants.
In building our gold standard model, all available claimant data was included, and claimants were excluded for (1) passing away, (2) having less than 30 timesheets, and (3) having cognitive needs.
Claimants that passed away were excluded because our preliminary data suggest these patients fit a different model. At this time, our sample size is too small to statistically separate these claimants into a future model, but we believe with more data, we will be able to build a model that predicts and anticipates their needs to identify claimants where focused interventions will minimize institutionalization rates at this critical stage.
Claimants with less than 30 timesheets were also excluded because our internal data has shown a high degree of variation in assessing our claimants’ needs when they are first enrolled in our system. These variations minimize as the relationship between the caregiver and claimant matures; we see the variation increase after a new caregiver is assigned or requested. Importantly, as the variance in assessments goes aways, these assessments converge on values predicted by our model. This will be published in a future paper.
Finally, our preliminary data has shown patients with cognitive needs fit a different model. We believe as we increase our sample size of patients with cognitive needs, we will be able to publish both models demonstrate their statistical differences.
The final data set was used to build our gold standard model. Both the assessments of our claimants’ needs and their intensity of utilization scores were plotted on a scatter chart using Tableau. Then a linear regression was applied to the data since it fit the data better than a polynomial regression. This gold standard model was then validated against two samples of data on opposite ends of the temporal spectrum to validate our model-independent of time, especially before and after our recent explosive growth in volume secondary to the COVID-19 pandemic.
To do this, we sampled 500 consecutive claimants from our earliest data, the “First 500,” and we sampled 500 consecutive claimants from our latest data, the “Last 500.” We then applied the same exclusion criteria used to build our gold standard model (detailed above).
Figure 1 shows the inclusion and exclusion of claimants from our “First 500” cohort. For the “First 500” cohort, we included our first 500 claimants. Fourteen claimants were excluded for passing away. Eight claimants were excluded for having less than 30 timesheets. Three claimants were excluded for having cognitive needs leaving 475 in the final data set for analysis.
Figure 1
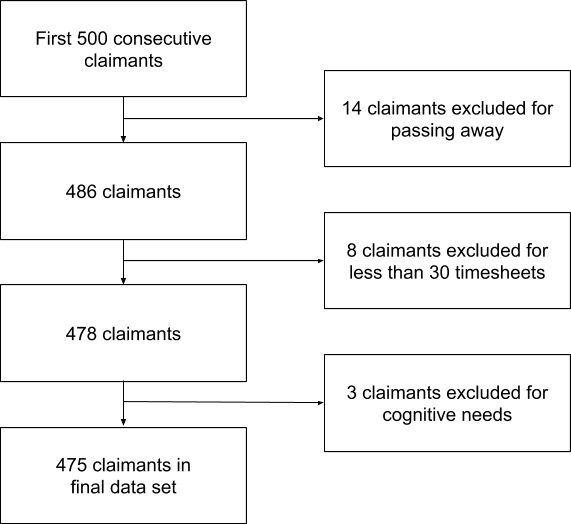
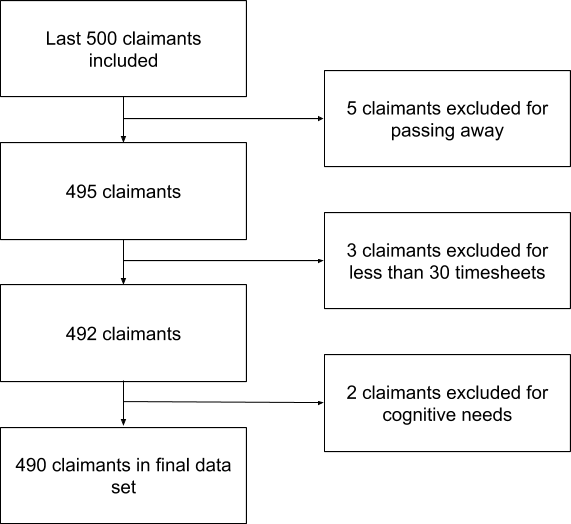
Figure 2 shows the inclusion and exclusion of claimants for the “Last 500” cohort, our most recent 500 claimants. Five claimants were excluded for passing away. Three claimants were excluded for having less than 30 timesheets. Two claimants were excluded for having cognitive needs leaving 490 in the final data set for analysis. Of note, the demographics between the two groups are comparable but not published for company and claimant privacy.
Figure 2
SQL was used to clean and pull the data from the databases, and then statistical analysis was provided by Tableau. Scatter plots were created for the final sets of data for both the “First 500” cohort and the “Last 500” cohort. The assessment scores of our claimants’ needs were plotted on the X-axis after their scores were normalized to a scale from 0 to 1 to mask our methods. The intensity of utilization scores was plotted on the Y-axis after these scores are normalized to a scale from 0 to 1, again, to mask our proprietary methods.
Using Tableau, a linear regression was applied to the scatter plots for both the “First 500” cohort and the “Last 500” cohort. These linear regressions were then compared against our gold standard model, which was created including our entire data set with the same exclusion criteria. Tableau was also used to determine if there was any statistical difference between either the “First 500” cohort or the “Last 500” cohort compared to the gold standard.
The figures and data for our gold standard model are not published to protect our trade secrets. However, our gold standard model demonstrates a very tight correlation between our scores representing the assessment of our claimants’ needs and our scores representing their intensity of utilization. The correlation has a calculated r2 value of 0.98, which is statistically significant. The linear regression has a slope of 0.89. This serves as the gold standard for comparing the data from the “First 500” and “Last 500” cohorts using the same statistical methods.
Figure 3 is the linear regression for our “First 500” cohort. After excluding a total of 25 patients, 485 remained in this data set. This linear regression also demonstrated a tight correlation with an r2 value of 0.985. The linear regression slope for the “First 500” cohort is 0.885, which is not statistically significantly different from our gold standard model.
Figure 3
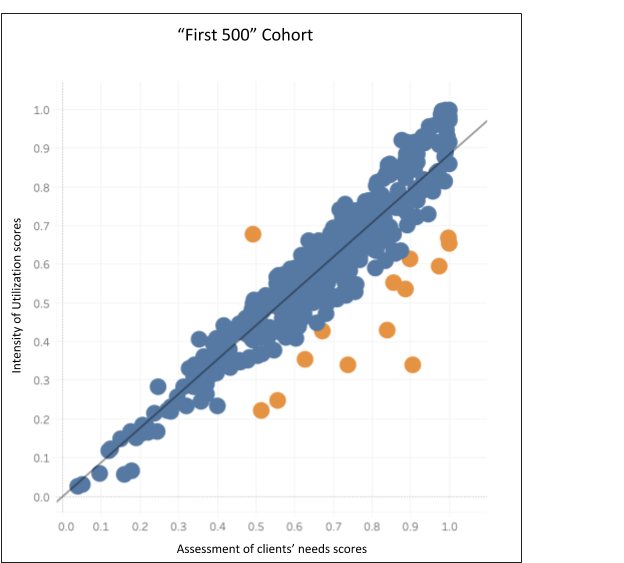
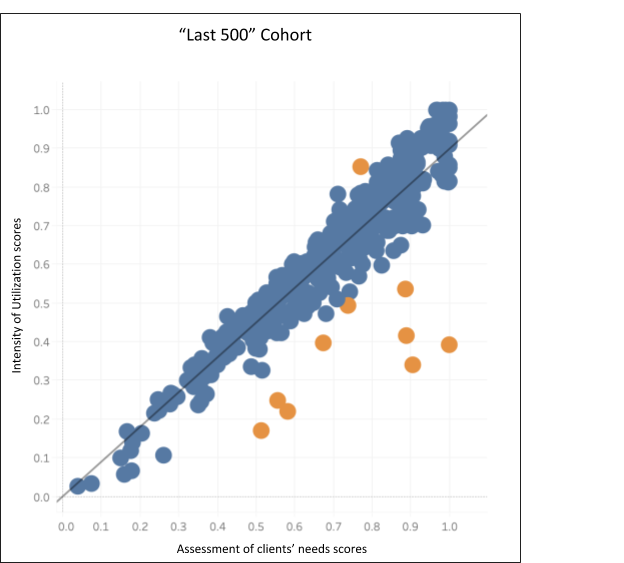
Figure 4 is the linear regression for our “Last 500” cohort. After excluding a total of 10 patients, 490 remained in this data set. This linear regression also demonstrated a tight correlation with an r2 value of 0.985. The linear regression slope for the “Last 500” cohort is 0.898, which is not statistically significantly different from our gold standard model.
Figure 4
Using our company’s model, we define claimants as outside the model (“outliers”) when their “intensity of utilization” is greater than 120% of our expectations or less than 80% of our expectations. With a 20% tolerance, our model predicts the “intensity of utilization” of more than 97% of our claimants. This means claimants that fall outside of our model are more than two standard deviations outside the mean. These data are not published to protect our trade secrets.
Applying this standard to the “First 500” cohort, 14 of 490 (2.9%)claimants fall outside of the model. These are the data points highlighted in orange in Figure 3. 1 claimant falls above expectations, and 13 claimants have an “intensity of utilization” score below expectations.
Applying these methods to the “Last 500” cohort, 10 of 485 (2.1%) claimants fall outside the model. These data points are highlighted in orange in Figure 4. 1 claimant exceeds expectations, and 9 claimants have an “intensity of utilization” score below expectations.
These figures closely match the findings of our global data set, where <1% of claimants exceed expectations, and 2–3% of claimants fell below expectations (data not shown).
The linear regression slope for our gold standard is 0.89 and demonstrates a very statistically significant correlation with an r2 value of 0.98. This means for every 10% increase in our assessment of a claimant’s needs; we anticipate an 8.9% increase in their intensity of utilization of services rendered. The lack of statistical difference between the “First 500” and “Last 500” cohorts’ linear regression models provides validation for our model independent of time. Long term care claimants are subject to several extrinsic factors, including a seasonal variation of illnesses, meeting deductibles, open enrollment dates, etc. The fact we can demonstrate our model is consistent independent of both time of year and the life of our company solidifies our model’s ability to predict our claimants’ needs based on our assessment of their needs. This also reassures us that our model scales with volume since sets of data were sampled before and after our explosive 9-fold increase in volume secondary to the COVID-19 pandemic.
This ability to predict and anticipate the intensity of utilization of services rendered based on our caregiver assessments makes the initial assessment all the more critical. Therefore, we designed our assessment to be the sum total of categories scored either a 0 or 1 by caregivers. These binary or yes/no assessments leave less room for subjectivity. These limited categorical assessments increase inter-rater reliability, which is demonstrated by high kappa scores. This is based on our preliminary data, which indicates that claimants’ assessments are consistent even when claimants change caregivers.
Whenever a new caregiver initiates service for one of our claimants, there is a temporary increase in the variation of our scores assessing claimants’ needs. Therefore their expected intensity of utilization scores is also off. But within 30 timesheets, this variation disappears, and our caregivers’ assessment converges towards the assessment of the previous caregiver. Subsequently, our claimants’ intensity of utilization scores converge towards expected values as well.
Unexpectedly there is a disproportionate amount of claimants whose “intensity of utilization” scores fall below expectations versus above expectations. When we developed our gold standard model, the difference was striking, with <1% of our claimants falling above expectations versus 2–3% falling below expectations. This dichotomy is even more pronounced when it is stated that out of all the claimants that fall outside the model, 95% are found below expectations and only 5% are found above expectations.
The reasons for this stark contrast are not immediately apparent. But when we sampled the first 500 claimants and the last 500 claimants, we see the same distribution of claimants that fall outside of the model. For the “First 500” cohort, of the claimants that fall outside of the model 93% (13 out of 14) are below expectations and 7% (1 of 14) are above expectations. Similarly for the “Last 500” cohort, of the claimants that fall outside of the model 90% (9 out of 10) are below expectations and 10% (1 out of 10) are above expectations.
When claimants fall below expectations, this could represent our over-assessment of their needs, or more dangerously, it could be a reflection of us not providing enough services for these claimants. Therefore, this subset of claimants that falls outside of our model and below our expectations is the perfect focus for reevaluation and early intervention by our in-house Care Concierge division. This division of The Helper Bees is specifically tasked with and dedicated to preventing institutionalization, accidents resulting in injury, emergency services utilization, etc.
Alternatively, when claimants fall outside of the model and their intensity of utilization scores exceed expectations, this could be a reflection of us under-assessing their needs or it could be investigated to rule out fraudulent billing or abuse of services.
The reason there is an uneven distribution of outliers above and below expectations is unclear. It could merely be a reflection of claimants’ inherent tendency to underreport their needs, similar to under reporting symptoms. They may be too embarrassed or proud to ask for more help. We hope presenting claimants with the data from our model will help remove the stigma surrounding asking for more help. We are confident this will reduce the number of claimants over-exerting themselves and putting themselves at risk for injuries, emergency services, hospitalization, and institutionalization. Currently, our sample size of patients who are institutionalized, suffer injuries from falls, or pass away is too small to see if we can determine a subset of claimants that are at high risk for these outcomes. But preliminary data suggests we will be able to, once we have enough data samples for each of these outcomes. Then we can launch a trial to see if early and intense interventions can decrease the incidence of these devastating and costly outcomes.
This could also reflect a hesitation on behalf of our claimants to appropriately utilize their caregivers in fear of incurring higher costs since the long-term care industry suffers from the same lack of transparency typical of health insurance. With larger and more diverse data from different insurance carriers, we plan to see if various insurance policies influence the intensity of utilization scores.
In the future, we will publish several additional white papers, investigating cases that fall outside of our model. As mentioned previously, we also plan to distribute data demonstrating the inter-rater reliability of our needs assessments when our claimants change caregivers.
We also are working on correlating our “intensity of utilization” scores to both the hours logged by caregivers on their timesheets, and subsequently, the actual claims billed to our insurance partners. Preliminarily, there is a surprisingly weak correlation between the number of hours logged by our caregivers and our assessment of our claimants’ needs. Therefore, we are developing a model that incorporates the services’ cost into our current model to better understand the distribution of our partners’ expenses.
Finally, we hope to use our learnings from building this model and apply it to patients with cognitive needs. These patients have a much more comprehensive range of considerations, making the assessment more difficult. The difficulty is further compounded by the requirement for a healthcare proxy who interprets the claimant’s needs. Nevertheless, we are focused on building a model that can predict the expected level of services necessitated by claimants independent of their need for cognitive help.
The Helpers Bees prides itself on being the ultimate partner for both our claimants and insurance carriers. We have transformed the long-term care industry by giving patients what they want: a system built around the desire to age in place. Care is individualized and custom-tailored to the needs of our individual claimants. At the same time, we increase revenues and decrease expenses for our insurance carrier partners. The Helper Bees can enhance the experience on both sides of the relationship between insurance providers and claimants. This transforms the traditional tug-of-war between claimants and insurance companies into a symbiotic relationship since incentives are now aligned.
Claimants and long-term care insurance companies equally want to avoid institutionalizations for their unique reasons. The Helper Bees not only decreases the rates of institutionalizations but enhances and optimizes the age-in-place options for our claimants. Concurrently, we provide dashboard-style data summaries of individuals that allow our insurance carrier partners to extrapolate trends in care/health, detect possible fraud, see policy usage, and detect changes in care. Additionally, we provide reports on aspects of the overall care block, such as cost savings, possible fraud, inactivity, and underutilization of care. These systems empower our partners to generate real-time reports on the fly, realize continuous ROI in a challenging and dynamic industry, and provide data-driven, personalized care. Most recently, it helped carriers visualize and adapt to the evolving impact of COVID-19 on home health.
Now we have developed and validated a model that augments these systems by successfully predicting and anticipating the needs of our claimants. Our model simultaneously identifies outliers that benefit the most from focused early interventions, re-evaluations, and fraudulent investigations. These models further enhance our ability to fulfill our mission of building a system around individuals who want to age in place safely and comfortably. Because Dorothy said it best, “There’s no place like home.”
Jitsen Chang, MD
Medical Data Scientist
Jessica Faulk
Data Scientist
Char Hu, PhD
Chief Executive Officer